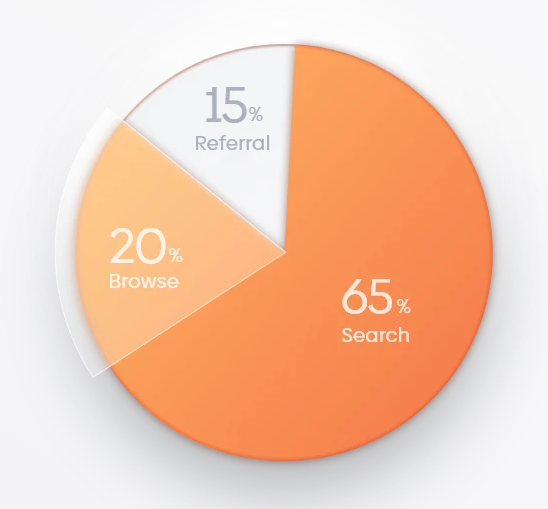
It’s tremendous easy: To be able to achieve success with cell advertising, you must know the science behind testing.
Testing is getting used all through the cell advertising funnel, for UA, Product, and ASO.
As an individual that’s within the weeds of ASO, you face a novel problem. Different digital entrepreneurs which can be tasked with bettering progress metrics normally management the setting they’re making an attempt to optimize. This may very well be a web site and even an app the place they’ll set up analytics options, measure how customers behave and reply to modifications, and act accordingly, hopefully driving enhancements within the KPIs they attempt to transfer.
As an ASO particular person, you’re tasked with driving enhancements on an asset you don’t even personal, your app retailer web page(s).
Because of this it’s unimaginable to run native assessments which can be akin to these assessments “different” entrepreneurs run. And these assessments are your solely device to drive ongoing enhancements, so getting them proper is vital to getting your job accomplished and rising.
We’re all happy to assume that in order to grow a successful mobile game (or app) you need:
Get into the science of it, however simply sufficient
Don’t make the error of diving too deep into the science of testing. As with every little thing in life, it’s vital to know the place to spend money on to make the utmost influence, and the place getting that additional mile may have diminishing returns. That is precisely the place it is best to apply the Pareto precept, nicely, type of, and make investments 20% of the time it requires to get to 80% of the experience degree you want. Attempting to get to that 100% experience degree will deter you from doing the stuff you actually need to deal with to maximise your progress.
That’s why we received you coated with this handbook, busting myths and uncovering some truths concerning the wild wild west which is the app retailer web page testing world.
That is the 20%. That’s my promise to you when you learn by way of this information.
What’s A/B/n Testing?
How does an A/B Check Normally Work?
An A/B check is a randomized experiment (within the sense that folks within the pattern – in our case app retailer guests – are assigned totally different variants at random). The core of the check is to match two variants and to carry out statistical hypotheses testing utilizing these variants.
All through this piece, we’ll look into probably the most beloved characters ever written for TV, Breaking Unhealthy’s Walter White, for reference, and to have some enjoyable. We like to consider our information scientists right here at ASOWorld as geniuses who’ve the identical degree of experience as Mr. White, albeit a lesser diploma of self-destructive conduct.
In our instance, Mr. White is questioning alongside together with his companion/mentee Jessie, whether or not blue meth will get extra consumers than white meth. As a science trainer, Mr. White will need to run an A/B check and decides that one of the best ways for that is to arrange two variations to promote – blue and white, on his darknet web site.
His null speculation is that “customers” might be detached to the colour of the meth.
That means that – H0: The conversion fee of the blue meth model is the same as the white meth model.
Nonetheless, Jessie tells him that blue meth “is the bomb”. So he kinds his various speculation.
H1: The conversion fee of the ‘blue meth’ is totally different than the white model.
Variant 1: The homepage will present easy white meth.
Variant 2: The homepage will present and focus on blue meth.
To run a correct A/B check Mr. White is aware of he must do one thing essential – to resolve on how many individuals to pattern all through the check, or in different phrases, set the pattern measurement upfront. With out doing so Mr. White gained’t be capable to know when it will likely be legitimate to cease the check and carry out statistical inference.
We have to set the pattern measurement upfront so that we are going to have a stopping rule that’s unbiased of the observations we get. You may all the time gather extra samples and the outcomes of the check will change. There’s a really sturdy relationship between the pattern measurement and the check end result.
So how ought to Mr. White decide the pattern measurement?
He first wants to find out these elements:
- The importance degree for the experiment
Studying this text, we are able to assume that you’re no stranger to testing, statistics and doubtless heard the time period “statistical significance” earlier than.
Bear with us. In simplified phrases, significance degree is a threshold for the likelihood to reject the null speculation (Customers are detached between the blue and white meth) when it was truly right.
In different phrases, in case that you just concluded that the blue meth is considerably higher, or worse, you need the prospect that you just’re mistaken to be 5% or much less. That’s how most individuals on this discipline function – the 5% significance degree.
There are a ton of points with selecting a 5% significance degree we gained’t go into, however the actuality is that it’s absurd. The 5% was given for instance in a well-known e book by Sir Ronald Fisher and was by no means meant to function a yardstick for all statistical assessments on the market. Why shouldn’t that quantity be 3%? 2%? 1%? Utilizing the identical pattern information, you would possibly get totally different outcomes primarily based on this quantity. Let’s dive a bit deeper:
- The Minimal Detectable Impact (MDE)
The MDE is the minimal change from the baseline you might be keen to simply accept as an precise change. Because of this in case your baseline conversion fee is 10%, and also you need to deal with ‘a change’ as at the least a 5% enhance or lower, you’ll deal with the vary between 9.5% to 10.5% (0.5%, which is 5% of 10) as indistinguishable from the baseline.
- The Baseline Conversion Fee
The baseline conversion fee of the management, merely the “precise” conversion fee that the management is exhibiting.
- The Statistical Energy
The check statistical energy is the likelihood of detecting at the least the distinction we simply specified because the MDE, assuming one exists. The decrease the facility the decrease the prospect we’ll by accident conclude that there isn’t a distinction between white meth and blue meth, whereas actually there’s.
The (first) huge drawback with A/B assessments
That’s probably the most widespread errors with A/B assessments – Assessments which can be being run with out a clear and stuck pattern measurement upfront. With out one, there’s no clear stopping rule to the check, and the second in time you resolve to conclude the check dramatically impacts the end result you’ll get. It’s principally cherry-picking and permitting your intentions to distort the outcomes of the check (As you may have a look at the outcomes and terminate the check when they’re handy).
Rejecting the null speculation (and discovering a winner within the A/B check) requires calculating a P-Worth (which stands for the likelihood to get a extra “excessive” end result than the one you bought). Whether it is decrease than the importance degree, the null speculation is rejected.
Mathematically, accumulating extra samples will lower the pattern variance, which can result in a decrease P-Worth. So just by ready and letting extra information circulate in, you might be artificially making it simpler to reject the null speculation.
The (second) huge drawback with A/B assessments
“Yo Mr. White isn’t that a variety of issues so that you can know. Like.. assume earlier than we, you understand, truly know something?”
“Sure, Jessie!”
The standards you could set upfront is anybody’s guess. To start with, most often, you don’t actually know the baseline conversion. Second of all, the Significance degree and Energy of the assessments are summary numbers that may be set in a different way by totally different folks, relying on their preferences. If totally different folks have a look at the identical information, utilizing the identical technique however with totally different parameters, and get to totally different conclusions, nicely, what did we do there?
This opens up a can of worms that enables check planners/managers to nearly assure a end result that’ll go well with them by rising the probability of false positives or reducing the one for true negatives (by taking part in with the importance and energy). Let’s proceed with our instance:
So, by utilizing 5% as the importance degree, 80% as the facility, 10% because the baseline conversion fee, and three% because the MDE, Mr. White calculated that he wants 157,603 samples per variation. Fortunately Mr. White has a ton of site visitors and might get that in per week. The check has been working for per week and solely after it reached 157,603 samples per variation, Mr. White closed it.
Check outcomes and arriving at a conclusion
The outcomes confirmed:
In accordance with
- White Meth Variation = 12.04% conversion fee
- Blue Meth Variation = 12.86% conversion fee
Mr. White then ran a proportion distinction check and calculated the check P-Worth. After that, he checked to see if the P-Worth is greater or decrease than the check threshold.
Because the P-Worth was decrease than 0.1%, he rejected the null speculation and concluded that there’s a clear person choice and that blue meth does carry a better conversion fee than white meth.
The end result allowed him to reject the null speculation (that there’s no distinction) and settle for that blue meth has a better conversion fee. Mr. White went on and utilized the blue meth variation on the homepage and waited to see the money rolls in.
A/B testing isn’t the one method to go, Bayesian Inference might help
“Yo, Mr. White yo,” stated Jessie with a mouth stuffed with smoke, “Didn’t you train us a few totally different statistics man that stated P-Worth is bullshit?”
“A statistics man?!?! Jessie!”
“Yeah, what was his identify, c’mon. Oh! Vase, I keep in mind it was Vase! What about him?”
“Bayes Jessie, Bayes”
Jessie’s remark received Mr. White to begin pondering concerning the check outcomes. “Am I certain that the outcomes are proper? May they be false positives?”.
He remembered an instance he used to elucidate the distinction to college students:
“Think about that you just’ve misplaced your cellphone however you understand for sure it’s someplace in your home. Instantly you hear it ringing in one of many 5 rooms. You recognize from previous experiences that you just usually go away your cellphone in your bed room”… What now? There are two choices:
Frequentist Reasoning
A frequentist strategy would require you to face nonetheless and hearken to your cellphone rings, hoping which you could inform with sufficient certainty from the place you’re standing (with out transferring!) which room it’s in. And, by the way in which, you wouldn’t be allowed to make use of that information about the place you normally go away your cellphone (within the bed room).
Bayesian Reasoning
A Bayesian strategy is nicely aligned with our widespread sense. First, you understand you usually go away your cellphone in your bed room, so you might have an elevated probability of discovering it there, and also you’re allowed to make use of that information. Secondly, every time the cellphone rings, you’re allowed to stroll a bit nearer to the place you assume the cellphone is. Your probabilities of discovering your cellphone shortly are a lot greater.
Within the Frequentist mind-set there are merely information collected by way of a check after which some inference primarily based simply on these information to get to a conclusion.
Within the Bayesian mind-set, there isn’t a “check”. There’s merely the gathering of information and the replace of your prior start line on how these information are distributed. Then you definately use an evaluation of the mannequin that resulted from this course of to make conclusions.
After checking the revenues from the previous two days after he applied the blue meth on his homepage, Mr. White noticed they didn’t actually change a lot in comparison with the earlier interval. He determined to verify once more himself and run one other experiment, this time primarily based on the Bayesian strategy.
Since this strategy depends closely on up to date information, he didn’t must set arbitrary parameters to run the check. He determined to account for the every day variation, so every single day on the similar time he appeared on the outcomes and up to date the calculated distribution of every CVR.
As an alternative of accumulating 157,603 samples per variations after which stopping the check, calculating the P-Worth after which evaluating it to the chosen significance degree, Mr. White’s Bayesian strategy guided him to principally draw out the distribution of every variant CVR (section 1), and with new information coming in every single day he up to date the distribution (section 2) to make it a extra correct reflection of the info he noticed.
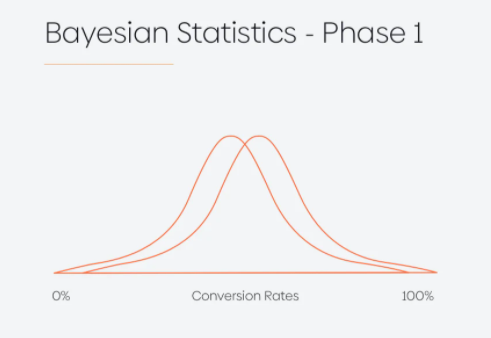
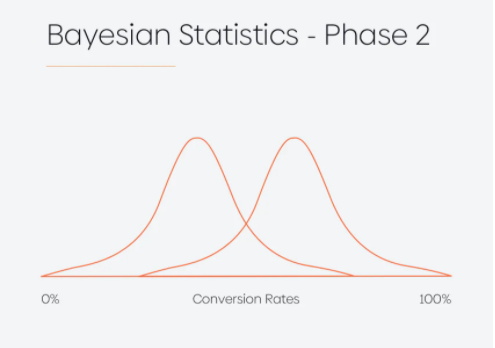
Because the conversion fee distribution curves began to seem extra distinct, he needed to make a conclusion. After per week value of information he might see the next scenario (section 3):
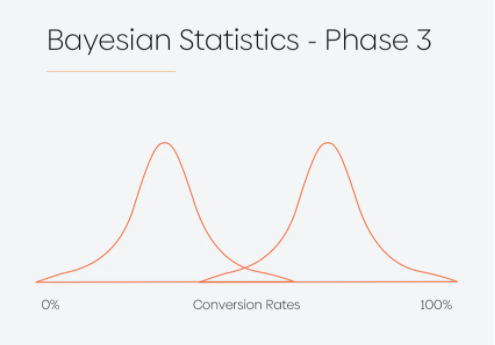
It appears that there’s a very low probability of the white variation changing at a better fee than the blue meth model. In actual fact, the prospect of it taking place is lower than 1%, and it possible might not convert greater than 2% greater than the blue model.
Happy by these outcomes, Mr. White closed the check, applied the blue variation and began to trace revenues.
Jessie and Mr. White drove to the horizon pleased with the outcomes. Mr. White calculated that they generated $1.4M greater than what they might’ve generated if they might be caught to the white meth model.
The 4 major testing strategies within the App Retailer market at the moment – which do you have to use?
Let’s go away Mr. White and Jessie to their recognized destiny and get again into our world of app retailer testing. There are 4 major methods to check app retailer pages at the moment:
- third occasion instruments that use classical A/B testing, the type we described within the first instance, the place a two-sided speculation was carried out to conclude the winner.
- third occasion instruments that use sequential testing, an alternate A/B testing strategy that tries to determine big-winners early on.
- Google Experiments that use their very own in-house developed frequentist strategy.
- third occasion instruments that use Bayesian-inspired testing.
1. Classical A/B Testing
How are you going to use such a check within the app shops?
There are some third occasion instruments that provide testing and use classical A/B testing as their statistical engine.
Conditions to arrange a check
- Select a significance degree
- Set the baseline
- Select an MDE (Minimal Detectable Impact)
- Select a statistical energy
- Use the above to calculate a pattern measurement
The likelihood to get the conditions proper
As we mentioned within the instance above, these three parameters that dictate the pattern measurement aren’t certain to nearly any principal. Everybody has the power to alter them and each change will drastically have an effect on the results of the check even when the info are the identical. There isn’t any purpose to notably select any particular parameter worth.
How inclined is it to errors or manipulation?
- Setting check parameters upfront in a fashion which isn’t per related elements, similar to site visitors traits, variety of variations, and so on. results in inferring the mistaken conclusion concerning the check outcomes.
- One of the crucial widespread errors is to begin working such a check with out a pattern measurement fastened upfront. This implies the check outcomes might be vulnerable to ‘cherry-picking’ because the check supervisor might have a look at the outcomes and wait till they attain significance after which shut them. This can extraordinarily enhance the probability of a false constructive.
Different drawbacks?
Normally, this technique requires a really giant pattern measurement. To drive such a pattern to a check utilizing a third occasion device will price tens of hundreds of {dollars} per check.
2. Sequential Testing
How are you going to use such a check within the app shops
There are specific third occasion instruments that provide testing and are utilizing sequential testing as their statistical engine.
The place did this technique come from?
Let’s set historical past straight: In accordance with on-line sources “The tactic of sequential evaluation is first attributed to Abraham Wald with Jacob Wolfowitz, W. Allen Wallis, and Milton Friedman whereas at Columbia College’s Statistical Analysis Group as a device for extra environment friendly industrial high quality management throughout World Warfare II…”.
Yup. This technique originated as a way to detect defective manufacturing strains throughout World Warfare II. Sequential testing helped manufacturing managers to detect abnormalities of their manufacturing strains as early as attainable, or in different phrases, to grasp the speed through which these manufacturing strains produce defective merchandise (initially weapons, tanks, and different merchandise) and alert them if there’s one thing mistaken in a particular line. Curiously sufficient this strategy was adopted by some within the app retailer testing market.
How does it work?
The tactic relies on repeatedly accumulating samples and early-on detect if there’s a winner which lets you cease the check early (earlier than reaching some fastened pattern measurement determined for the check).
It’s totally different than classical A/B testing within the sense that it permits you to ‘save’ samples in sure eventualities (which can dive into in a sec). That being stated it has many drawbacks, a few of them relate to the character of the tactic and a few of them relate to the identical drawbacks of classical A/B testing.
Conditions to arrange a check
Set a set pattern measurement by deciding and setting:
- Significance degree – The identical ‘loaded’ time period we mentioned earlier than which many on the planet select to be 5%, for no good purpose apart from routine.
- Minimal detectable impact – On this strategy, it’s straightforward to intuitively perceive what that is. Initially it’s the suitable threshold for manufacturing strains fault charges. On the earth of app retailer testing, it loses its that means as there isn’t a such threshold (wouldn’t you be pleased with a 2%, 3%, 4% enhance in efficiency)?
- Statistical Energy – The identical time period from classical A/B testing many of the world select to be 80%, once more for no good purpose apart from routine.
- Baseline Conversion Charges – To calculate the dimensions of the pattern wanted to drive to the check you could set the baseline conversion of your app retailer web page, which is, after all, unimaginable to do earlier than beginning to pattern a site visitors supply.
The likelihood to get the conditions proper
As a cell marketer, totally different mixtures of those parameters might and sometimes will end in a special conclusion (totally different winners, or no winner in any respect).
As well as, estimating your conversion charges upfront is just about unimaginable, and when you’re mistaken, which you’ll solely know after beginning to run site visitors to the check, the pattern measurement that you just initially set might be invalid, making the check invalid in flip.
Some instruments truly attempt to “hack” this by updating your pattern measurement because the check progresses (by what are the precise baseline conversion charges). This can be a strict violation of the precept of setting a set pattern measurement upfront, resulting in ‘cherry-picking’ or altering the “stopping rule” to suit your wants, creating very skewed outcomes.
How inclined is it to errors or manipulation?
- Setting the parameters upfront is an unimaginable feat. The parameters will management how lengthy the check will run which might end in totally different winners as a perform of the incoming site visitors at every time level. This alone opens up a lot room for debate on the validity of the outcomes and clearly reveals how inclined these assessments are to yield false outcomes (both a winner that’s not an actual winner, or a failure to discover a winner when actually there’s one).
- Sequential testing shouldn’t be an amazing match for app retailer web page testing because the weakest factors are, quoting from Evan Miller who wrote an in depth article on this:
- “The process works extraordinarily nicely with low conversion charges. With excessive conversion charges, it really works much less nicely, however in these circumstances, conventional fixed-sample (i.e. classical A/B testing) strategies ought to do you simply nice”.
- “The sequential process introduced right here excels at shortly figuring out small lifts in low-conversion settings — and permits profitable assessments to be stopped early — with out committing the statistical sin of repeated significance testing. It requires a tradeoff within the sense {that a} no-effect check will take longer to finish than it could underneath a fixed-sample regime”.
- “The process works extraordinarily nicely with low conversion charges. With excessive conversion charges, it really works much less nicely, however in these circumstances, conventional fixed-sample (i.e. classical A/B testing) strategies ought to do you simply nice”.
These two weaknesses are precisely the phenomena which can be prevalent in-app retailer web page testing. The typical conversion fee of most site visitors sources used with app retailer testing (utilizing a third occasion device) is normally not low (Evan Miller factors out to low as being sub 10% and in lots of circumstances sub 5%). This implies these assessments gained’t truly shut quicker than different strategies. Furthermore, in circumstances when there isn’t a transparent winner, these assessments will take for much longer to conclude. In lots of phases of testing as a cell marketer, you face assessments that present that customers are detached to totally different variations, that are assessments that contribute loads to your studying in the direction of the subsequent assessments.
Different drawbacks?
Above all, a testing technique that requires you to veer away out of your core competencies, and takes a variety of effort from truly pondering creatively about messaging and attending to know your customers and places it into determining statistical parameters, isn’t a constructive contributor to your efforts in the long run. Why do you have to resolve testing by yourself?
3. Google Experiment Testing – Scaled Installs
How does it work?
Google Play Customized Retailer Itemizing Experiments will let you set as much as three variations (not together with the obligatory present retailer design), set the share of site visitors that every variation will get after which begin working the check on 100% of the inhabitants that matches the check standards (both international, by nation, or by language).
After the check begins working, in some unspecified time in the future Google Experiments present you many metrics for every variation:
- Precise Installs – The precise variety of installs that the variation generated.
- Scaled Installs – The theoretical variety of installs that the variation would’ve gotten if it was set to obtain 100% of site visitors.
- Retained Installs (Day 1, Day 7, Day 15, Day 30)
- Confidence Interval – The vary of raise/lower from the present variation through which the “true” raise worth lies. The arrogance degree is 90%
Conditions to arrange a check
- Deciding on the share of site visitors that every variation will get. There’s additionally no fixed pattern measurement set upfront, however using the Confidence Interval metrics, which factors to the truth that Google’s strategy right here is frequentist.
The likelihood to get the conditions proper
As there aren’t any statistical check associated parameters to set, it looks as if Google Experiment is a black field, and there’s no clear visibility into the statistical calculation they make on the info to get these Confidence Intervals. That being stated, with out a fastened pattern measurement, the check is vulnerable to the Cherry Selecting errors, which implies the check managers will carry on checking the outcomes of the check till they really feel it’s conclusive, normally when the outcomes serve their function.
How inclined is it to errors or manipulation?
- The statistical validity of the boldness interval is questionable – as it’s primarily based on the scaled installs metric which isn’t actual, however theoretical. A incessantly noticed phenomenon within the business is a unfavorable correlation between the impression quantity and conversion fee. The upper the impression quantity, the decrease the conversion fee. So assuming scaled installs will develop linearly from the precise installs determine is kind of an enormous assumption. One other downside right here is that inflating the metric values additionally lowers the variance, which makes it simpler to achieve significance.
- We don’t actually understand how Google calculates the boldness interval, which implies we don’t precisely perceive how error-prone is that calculation.
- The dearth of a set pattern measurement opens up every experiment to a major human-error which we identified to. That is the ‘cherry-picking’ error, or the fixed checking of check outcomes previous to closing it as soon as the outcomes fulfill the check supervisor.
Different drawbacks?
The truth that Google Experiment makes use of a significance degree of 10% implies that the outcomes they do visualize by way of the Confidence Interval are supposedly 90% more likely to be right which renders most of the outcomes you see just about ineffective as a decision-making device, and that is the best-case state of affairs, as we are able to’t validate their statistical assumptions.
4. Bayesian Testing
How are you going to use such a check within the app shops
ASO World has developed the StoreIQ methodology that’s primarily based on Bayesian statistics.
How does it work?
The world of digital expertise testing is transferring quick into Bayesian statistics and inference. Even Google themselves, with the event of the world-leading testing product for net experiences, Google Optimize 360.
Wait, what? Didn’t we are saying that Google Play Customized Retailer Itemizing Experiments is utilizing frequentist statistics?
Yup, though we are able to’t know what goes on on the again finish of Google Experiments, they’re relying closely on a frequentist methodology for inference. There may very well be many causes for that, however above all Google is a really giant firm with a whole lot of merchandise, and a few of these merchandise get extra improvement sources and a few much less. Implementing Bayesian statistics and inference in a testing product requires immense computation energy and infrastructure funding.
Google explains it higher than us right here: how to make your app popular.
So, what’s Bayesian inference?
Bayesian inference is a elaborate means of claiming that we use information we already need to make higher assumptions about new information. As we get new information, we refine our “mannequin” of the world, producing extra correct outcomes.
Bayesian Inference works in a different way than frequentist testing that’s closely centered on offering a p-value. In actual fact, Bayesian Inference doesn’t require a p-value in any respect. The method appears one thing like this:
- Acquire uncooked information, in our case observations on customers touchdown on one of many app retailer web page variants and monitoring whether or not a person selected to put in or not.
- Estimate the conversion fee (CVR) distribution of every variation utilizing the info collected. The distributions might be instrumental in estimating which variation is the most certainly to have the most important CVR.
- Recurrently, gather extra information and replace the CVR distributions. On this sense, the mannequin adapts to new information and updates our ‘view’ of how that variation CVR distribution curve appears like.
- As you gather extra information the distribution curves of every variation turn out to be extra clearly outlined.
- Recurrently examine statistics that relate to those distributions and examine the possibilities that one variation will generate conversion charges which can be greater than all others.
- After we can conclude that one variation’s CVR distribution is clearly exhibiting that it has a really small likelihood of surpassing the main variation we are able to shut down that variation, and cease sending site visitors to it, which saves important site visitors prices.
- As soon as we conclude that there’s a very excessive likelihood that one variation’s CVR distribution curve will result in greater conversion charges we are able to clearly name a winner.
Conditions to arrange a check
There are none that you could fear about!
You learn it proper. Bayesian statistics don’t assume you understand something concerning the significance degree, statistical energy, the minimal detectable impact or the required pattern measurement. As a result of… you don’t.
The likelihood to get the conditions proper
As there aren’t any conditions the likelihood to get them mistaken is 0%.
How inclined is it to errors or manipulation?
Among the many obtainable strategies at the moment, and the clear course of the general digital testing business to maneuver into Bayesian Inference fashions we strongly imagine that that is essentially the most correct technique to check app retailer pages.
Different elements to contemplate
- By utilizing StoreIQ we save essentially the most quantity of site visitors attainable with out sacrificing accuracy, as we are able to clearly see that sure variations CVR distribution curves are “far” from turning into a winner and cease sending site visitors to them.
- This technique isn’t delicate to cherry-picking because the distributions are typically extra outlined as you gather extra samples, and there’s no p-value that dictates the results of the check.
- You’re avoiding the potential of altering check outcomes by setting totally different significance ranges, energy, or MDE ranges, they merely aren’t part of the decision-making course of.
Why it’s extra essential to ensure you’re not getting false positives with App Retailer Testing
It’s extra about high quality than amount.
Previously period of app retailer optimization and advertising, many opted into testing fairly often, hoping to see a transparent winner, to the bliss of all the workforce. The leads to the real-store had been uncared for as there have been fewer methods to quantify the influence of inventive updates.
In the present day that’s not sufficient. Many ASO groups and cell advertising groups have began to deal with it as natural person acquisition. As with person acquisition, the KPIs groups are being evaluated on are cold-hard set up metrics, extra particularly natural installs.
On this world, to succeed as a cell marketer or as an ASO supervisor, you could drive outcomes, and so as to do this, one of many prime instruments in your arsenal is inventive testing, enabling you to extend the conversion charges for essentially the most helpful viewers.
Spending a whole lot of hours, and tens of hundreds of {dollars} to run assessments which can be inherently flawed is like taking part in Russian-roulette along with your career-growth. Why tie your success to testing strategies which can be recognized to supply a big chunk of false outcomes?
There’s additionally the choice price of investing time in assessments that produce questionable outcomes. You might have a lot better alternate options to spend your time.
Sourcing from: How Media Teams Can Thoughtfully Balance Liquidity and Control