Clear processes for secondary analysis are uncommon. Some concepts on learn how to enhance the way in which designers gather and doc present data.
Table of Contents
A standard reply I received whereas speaking to round 47 designers, managers and researchers, throughout Europe about their analysis course of. More often than not, their efforts are centered on validating already developed options, and virtually by no means encourage the sooner discovery course of. This will get much more tough when designing for international markets. Except there’s a devoted native workforce, analysis will get fairly scarce. It finally ends up being outsourced to a number of businesses a few occasions a yr.
The fact is that we not often have the possibility to run exploratory analysis research earlier than sketching out any concepts. How can we then construct a basis primarily based on information and insights earlier than we begin drawing the primary sketch? That’s the place secondary analysis is available in. When carried out properly, it could instantly reveal whether or not you’re reinventing the wheel, repeating errors, and opening up a world of earlier data any person else tried out.
Personally, I’ve not seen or skilled a transparent course of that makes use of secondary desk analysis. There at all times appears to be a mixture of posting screenshots on a wall, studying a couple of articles, and repeating some generic design rules. Regardless that I don’t know the way secondary analysis must be applied inside a working course of, I do know that we first want a extra constant means of accumulating and documenting present data, earlier than we purpose to create our personal. So, I began making it myself.
How a lot information ought to we glance into?
Sure. We underestimate the quantity of accessible info we may use earlier than diving into visible work: Youtube movies, scientific analysis, idea designs, articles written by design groups, information, key phrase traits. I imagine we underestimate it since we’re principally biased at searching for the channels we already use. We’re lacking on variety in information since we’re each selecting the supply of knowledge and the knowledge itself.
What if we merely search for the knowledge inside a search engine with predefined, wealthy sources of knowledge and insights? Shortly put, use a refined aggregator tailor-made for secondary analysis for product designers.
Imagining that each one these APIs could be available, folks may merely ask for a particular subject they’re designed for, e.g. “Apple Carplay” and the aggregator would return a various set of outcomes on the subject. Ideally, these would even be pre-sorted into classes as influencer movies, advertising and marketing movies, patents, analysis papers, information, and many others.
Filtering could be carried out particularly per every API functionality. Folks can search for particular information inside June 2020 — July 2020, and every API will use no matter it could inside that enter to return filtered outcomes.
What can we do with the information?
I confirmed the straightforward diagrams above and some extra, to a few of the 47 folks I talked to initially. They had been fairly curious and eager on discussing a couple of factors:
- Outcomes shouldn’t comply with primary search engine optimization guidelines, e.g. a video with probably the most views may comprise much less fascinating information than one with a couple of hundred. mixture of content material have to be thought-about.
- Filtering on sub-topics, location, dates, information sorts, and extra, all of which might permit their search outcomes to develop into extra exact and simpler to make use of as arguments of their work.
- What’s going to a designer do with all of the search outcomes? A set of tabs, or a listing of hyperlinks?
- There was additionally the query of letting folks know that their content material is used for analysis. How would you inform a content material creator that they had been utilized in a analysis research? Do you even need to?
Wouldn’t this simply appear to be Google?
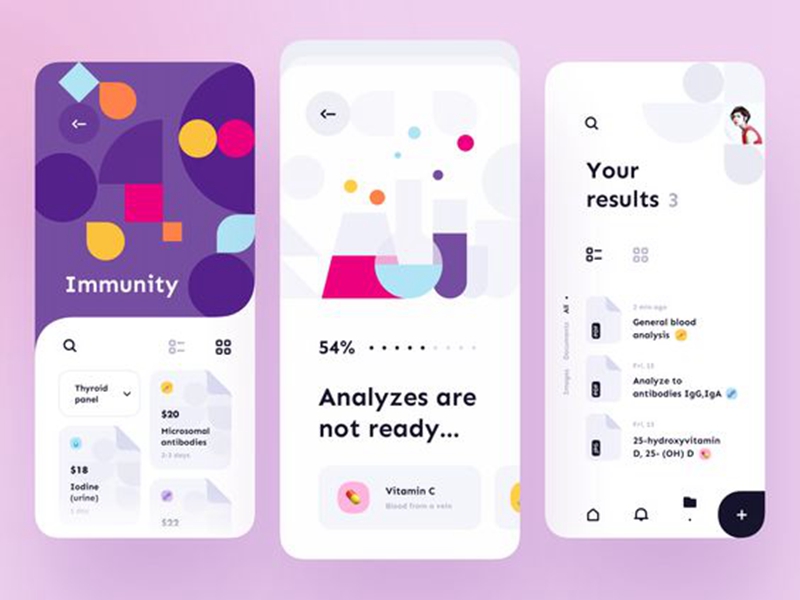
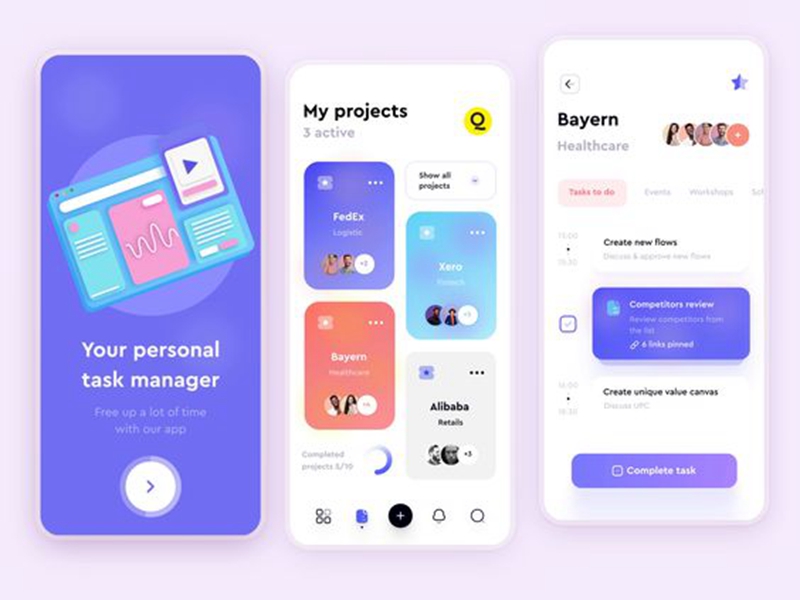
Having a construction set, and a few early suggestions I gave the visible half a attempt as properly. Began with a extra primary wireframe moved in direction of excessive constancy designs slowly.
I wished it to really feel easy, accessible, but in addition skilled, virtually lab-like. It got here out a bit boring for now, however I really feel prefer it’s happening the best path.
Subsequent steps
That is the place I ended for now. Realistically, there are only some available APIs, which I included within the designs above. My subsequent aim could be to complete the primary spherical of designs, check it with a couple of designers I do know and extra designers that I don’t know but :), then construct a working prototype and see how this aggregator impacts my work. Does it really assist to get a bit extra numerous information in a single place? Does it really feel unnatural and would it not are available the way in which of pure “googling”? Let’s see…